
In the world of cloud contact centers, there is no sound more terrifying than silence—specifically, the silence of a failed API call during your busiest hour. If your Amazon Connect instance is throwing intermittent 503 “Service Unavailable” errors, you aren’t just losing data; you’re losing customer trust.
As an AWS Solutions Architect, I’ve seen this happen to the best of us. The good news? A 503 isn’t a “your code is broken” error; it’s a “your infrastructure is breathing too hard” signal.
Here is your survival guide to diagnosing the cause and implementing the cure.
The Issue: Why “Service Unavailable” Happens at Peak
An HTTP 503 error in Amazon Connect typically occurs when the service—or a downstream dependency like AWS Lambda—cannot handle the volume of requests. During peak traffic (think Black Friday or a sudden service outage), two primary culprits emerge:
- Throttling at the Interface: You’ve hit the API rate limits for Amazon Connect.
- Downstream Bottlenecks: Your Lambda triggers are hitting concurrent execution limits, causing the Connect Flow to fail when it can’t get a response.
The Audit: Checking Your Service Quotas
Before writing a single line of code, you must know your limits. Many 503 errors are simply the result of outgrowing your default AWS sandbox.
1. Identify the Constraint
Navigate to the AWS Service Quotas console. You need to check two specific areas:
- Amazon Connect: Look for “API request rate” limits.
- AWS Lambda: Look for “Concurrent executions.” If your Lambda is used by multiple flows, a spike in one can starve the others.
2. Request an Increase
If your CloudWatch logs show ThrottlingException or Rate exceeded, don’t try to code around it yet. Submit a quota increase request. AWS often automates these approvals for established accounts.
The Cure: Implementing Exponential Backoff in Lambda
If your quotas are healthy but you’re still seeing intermittent spikes, you need to implement Exponential Backoff with Jitter.
Standard retries (retrying every 1 second) can actually make a 503 worse by creating a “thundering herd” effect—where all failed requests retry at the same exact moment, crashing the server again.
The Logic
Instead of a fixed delay, we use a formula where the wait time grows exponentially:
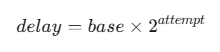
The Python Implementation (Boto3)
Most AWS SDKs have built-in retry logic, but for custom Lambda triggers or external API calls within your flow, you should implement it explicitly to ensure resilience.
import time
import random
def call_with_backoff(api_func, max_retries=5):
for i in range(max_retries):
try:
return api_func()
except Exception as e:
if "503" in str(e) or "Throttling" in str(e):
# Calculate delay: (2^i) + random jitter
wait_time = (2 ** i) + random.uniform(0, 1)
print(f"Retry {i+1} after {wait_time:.2f}s...")
time.sleep(wait_time)
else:
raise e
raise Exception("Max retries exceeded")Checklist: Why This Matters for Your Tech Stack
To ensure your contact center stays visible and functional, remember these SEO-inspired best practices for your documentation and error handling:
- Monitor Search Intent: Are your agents searching for “Connect slow” or “Connect 503”? Use CloudWatch Alarms to map these terms to specific error codes.
- Structured Logging: Ensure your Lambda logs include the
RequestId. This is your “keyword” for tracing errors through the AWS ecosystem. - Latency as a Ranking Factor: Just as Google ranks fast sites higher, Amazon Connect flows with high latency lead to “stuck” contacts and dropped calls.
Final Thoughts
The 503 error is a rite of passage for any scaling Amazon Connect instance. By auditing your Service Quotas and implementing Exponential Backoff, you transition from a reactive “firefighting” mode to a proactive, architected solution.
Also check – How to Fix Amazon Connect ICE Collection Timeout in CCP